さて、というわけでタイトル通り、件のwjnの書き手を本文から予測してみました。内輪ネタです。 使った主な言語、ライブラリは次の通り。
- Python3
- Beautiful Soup4 (データ取得)
- Janome (形態素解析)
- Tensorflow (深層学習)
コードはこちらgithub.com/hanarchy/DetectWjnAuthor
私は自然言語処理や深層学習の専門家ではないため、誤った説明になっているかもしれないので、予めご了承下さい。あと、深層学習とか言って全然深層じゃないです。
背景
wjnとは
偉大なニュースサイトです。
週刊実話 http://wjn.jp
その名の如く、実話のニュースを扱っています。その中の人気コンテンツの1つである、
[実録]女のSEX告白。
このコーナーは2名の書き手によって成り立っています。 それがかの偉大な柏木春人氏、奈倉清孝氏で、この両名は「力の柏木、技の奈倉」とまで呼ばれています。
以下、奈倉柏木研究室より抜粋
週刊実話Weeklyの人気小説記事「【実録】女のSEX告白」には二人の執筆者がいる。
一人は「柏木春人」 自身でも「美姉妹調教 姦る!」などの人気官能小説を筆頭に数多くの官能小説を執筆しているマドンナメイト文庫の人気ライターである。 妻、未亡人、姉等年上のエロスを得意とする。多少強引なシチュエーションでも独特の語り口調と引き締まった軽やかな文体は濃厚なエッチシーンというよりは淡白であっさりしていて読み手の想像を引き立つように書かれているのが特徴である。
もう一人が「奈倉清孝」 彗星のごとく現れ、現在では週刊実話専属のライターと伺える。あまりに詳細がベールに包まれているのでゴーストライターや色々なライターの集合体ではないかと疑われている。 過去にファンタジー系の小説を目指し「赤と緑」というタイトルのネット小説があがっているが本人かどうかの確認は取れていない。強引なシチュエーションであっての文のスピード感とその匠な擬音から一気にエロスの世界へ飛び込ませてくれる。また彼の魅力的な独自の言い回しに心を打たれた人も多い。その勢いと技を武器に現在人気は高くなってきている。
問題点
実録シリーズは特に2chを中心としたネット上で人気で、しばしばスレが立てられます。 しかし、スレ立て人が巧妙に「書き手を隠し投稿する」という問題点があります。 そのためスレは混乱し、レスの殆どが「これは奈倉」「柏木余裕」というレスに溢れ、いわば奈倉柏木当てクイズ状態になってしまっています。
その佳境の中で住民は両名を見分ける術を開発してきました。
43 名前: キングコングニードロップ(空)@転載は禁止 :2015/07/09(木) 14:30:40.03 ID:Gj/ziKBH0
奈倉、柏木両先生の見分け方
・オチンポが好きなのが奈倉、ペニスが好きなのが柏木。
・急展開があるのが奈倉、淡々と進むのが柏木。
・行為の最中に終わるのが奈倉、行為後の描写があるのが柏木。
・女が叫ぶのが奈倉、女がキレるのが柏木。
・擬音で済ませるのが奈倉、詳細に説明するのが柏木。
しかし、それでも精度は高くなく、検索するとこんなツイートが見受けられました。
柏木と奈倉を瞬時に判断するAIの開発が待たれるな
— 鋭利な刃物マン (@Ericamajitenshi) 2016年9月22日
そこで、私は流行りの深層学習による、記事本文から奈倉柏木の判定を行うAIを開発することにしました。 本記事では、データの取得から結果が出るまでを順を追って説明していきます。 スクレイピングによるデータの取得、データからベクトルにする手法、Tensorflowによる学習について述べていきます。
データの取得
wjnから記事本文を取得します。 今回はBeautifulSoup4を用います。BeautifulSoupの使い方はここでは説明しません。 流れとしては
- 記事URL一覧の取得
- 記事URLにアクセスして本文を取得
- 本文から書き手を抜き出しラベル化
のようになります。
今回、記事のURL一覧をwjnサイトのエンタメカテゴリから取得し、タイトルに「官能小説作家書き下ろし」とある記事のURLを取得しました。しかし、ここに登録されている記事は1000件なので、その中から得られた実録シリーズの記事は300件程度になってしまいました。
google検索でsite:wjn.jp/article/detail "官能小説作家書き下ろし"という風にやると2000件程度出てきたので、データ数を増やす余地があります。
文章からベクトルへ
さて、抜き出した本文の文章からニューラルネットに入れるにはどのようにしたらよいでしょうか。 前章で取得した本文は当然ですがそのままニューラルネットワークに入れることはできません。 したがって、文章の固定長ベクトル化が必要になってきます。 有名な手法としてはword2vec(手法?ライブラリ?)などがあります。 今回は手っ取り早くやるため、BoW(Bag of Words)という手法で文書をベクトル化しました。
流れは
- 本文を形態素解析を用いて単語で区切る
- 奈倉・柏木氏を特徴づける頻出単語を辞書化
- 辞書に単語で区切った文書を通して、ベクトル化(BoW)
BoWはさておき、これらの手法は英語のような単語同士が区切られている文章に適用できます。 日本語でこれらの手法を用いる際は、文章を単語に分ける、形態素解析を行う必要になります。 pythonにおいて形態素解析の有名なライブラリがいくつかありますが、今回はPyPIだけで簡単に導入できる、Janome(蛇の目)を用いました。
BoWは、単語を羅列した辞書を用意し、当該文章を構成する単語が辞書の中に登録されているか見て、ベクトルの中身を変更するものです。説明が下手なので実際に例を挙げてみましょう。
辞書: ムスコ 射精 ウィンナー 花吹雪 文章1:起死回生のため今度はウインナーを注文し、彼が来たとき「君のムスコさんは元気?」と軽く股間に触れました 文章2:紅白歌合戦の最後に花吹雪が噴き出すのに合わせて射精
| 辞書 | ムスコ | 射精 | ウィンナー | 花吹雪 |
|---|---|---|---|---|
| 文章1 | 1 | 0 | 1 | 0 |
| 文章2 | 0 | 1 | 0 | 1 |
のようになります。この数値は01だけでなく出現回数の場合もあります。今回は、出現するかしないか、すなわち01でベクトル化しています。
続いて辞書を作成していきます。特徴的な単語を辞書にしたいですよね。 ここでよく用いるのがTF-IDF特徴量で、TF値(全単語中に出現する単語の頻度)とDF値(全文書中に当該単語が出現する文書の頻度)の逆数をかけたものです。つまり、TF-IDF値が高い単語は「ある単語がある文章中で多く出現し、その単語は他の文書であまり出現しない」単語です。 今回の問題でいえば、「出現頻度が高く、奈倉氏・柏木氏を特徴づける単語」を抽出できます。 あ、もちろんこの辞書には「柏木」「奈倉」といった名前は入ってませんよ。
(まあ、今回word2bowの存在を知らなかったため、実装するのが面倒でTF-IDFは使わず適当に出現頻度と柏木奈倉率それぞれに閾値を設定して、それを満たした単語を辞書としています。)
参考:柏木氏、奈倉氏の頻出単語の違い
さて、先ほどの形態素解析を用いて355件の記事本文を解析し、せっかくなので頻出単語を抽出してみました。 この節で出た結果は、のちの学習には用いませんが、非常に面白い結果が出たので、この節は飛ばさず見てほしいです。
性器の表現
数字は出現回数を意味しています。どれも顕著に傾向が出ています。 まず乳房の表現を見てみましょう。奈倉氏はオッパイ、と直接表現はせず、カップ、乳首と表現されています。特に乳首攻めが好きみたいですね。ひらがな「おっぱい」は多分途中で区切られたか、出てきませんでした。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| 乳首 | 81 | 11 | 70 |
| カップ | 20 | 1 | 19 |
| オッパイ | 20 | 15 | 5 |
下半身です。 男性器の表現に着目してみると、特に柏木氏が多いように感じます。 チンチン、巨根は柏木氏がよく使います。 男根をよく描写するのが柏木氏の特徴なのかもしれません。 ちなみに「オマ」や「ンチン」って表示されているのは、本文側が伏字にしているため仕様です。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| アソコ | 222 | 131 | 91 |
| 股間 | 125 | 105 | 20 |
| 下半身 | 27 | 5 | 22 |
| 性器 | 23 | 8 | 15 |
| クリ | 32 | 17 | 15 |
| クリトリス | 80 | 12 | 68 |
| オマ | 56 | 54 | 2 |
| ペニス | 473 | 287 | 186 |
| ンチン | 44 | 39 | 5 |
| 巨根 | 21 | 20 | 1 |
| 男根 | 15 | 3 | 12 |
下着の表現
続いて、下着の表現を調べてみました。驚くべきことに、はっきりと差が出ています。 パンティーでは拮抗していますが、パンツ、ブラ、ショーツといった単語はほぼ奈倉氏から出てきています。特にショーツは柏木氏から一切出てきません。下着が描かれていたら奈倉氏の色が強いみたいです。実際に自分で書き手予想をするとき、下着の表現で判断すると8割方正解します。 ちなみに、男性用の下着のブリーフは柏木氏の方が多いですね。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| パンツ | 104 | 10 | 94 |
| パンティー | 60 | 29 | 31 |
| ブラ | 40 | 4 | 36 |
| ショーツ | 33 | 0 | 33 |
| ブリーフ | 22 | 18 | 4 |
| ストッキング | 16 | 0 | 16 |
役職、人物の表現
さて、今度は人物についてみてみましょう。 これも非常に顕著な結果が出ています。 先生、彼氏、課長、社長などといった役職や人物の表現が圧倒的に柏木氏の方が多いです。 こういった人物像を思い浮かばせる、シチュエーション重視なのが柏木氏の特徴なのでしょう。 だからと言って、こういった役職は同じ記事で2人称として何度も用いられるため、DF値としては低く、判断材料にはなりにくいです。自身で判断する場合も、役職が書いてあるから柏木だ、と安易に決めると間違えることが多いです。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| 先生 | 145 | 97 | 48 |
| 彼氏 | 95 | 67 | 28 |
| 課長 | 92 | 79 | 13 |
| 社長 | 71 | 43 | 28 |
| オジサン | 62 | 49 | 13 |
| 先輩 | 58 | 49 | 9 |
| 主人 | 49 | 18 | 31 |
| 部長 | 51 | 46 | 5 |
| 店長 | 46 | 31 | 15 |
| 旦那 | 38 | 20 | 18 |
| 主婦 | 37 | 26 | 11 |
| 友達 | 30 | 27 | 3 |
| 大学生 | 21 | 17 | 4 |
| 人妻 | 18 | 14 | 4 |
| 主任 | 16 | 16 | 0 |
| 大家 | 11 | 11 | 0 |
奈倉氏のストーリー
また、頻出単語から奈倉氏の記事のストーリーみたいなものが浮かび上がりました。 下の票のように、強引、叫ん、許し、痛い、これらの単語は強姦をイメージさせられます。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| 強引 | 43 | 6 | 37 |
| 叫ん | 37 | 5 | 32 |
| 許し | 39 | 9 | 30 |
| 痛い | 37 | 4 | 33 |
その一方、優しく、交際、結ば、妊娠、幸せ、告白といった単語がよく見られます。 このことから奈倉氏のストーリーでは「強引にするが、最終的には合意SEX」なストーリーが思い浮かびあがります。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| 優しく | 69 | 17 | 52 |
| 交際 | 18 | 0 | 18 |
| 結ば | 18 | 0 | 18 |
| 妊娠 | 12 | 3 | 9 |
| 幸せ | 33 | 13 | 20 |
| 告白 | 30 | 11 | 19 |
でも、一緒にイクわけではないらしいです。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| 一緒 | 69 | 56 | 13 |
絶頂の表現
奈倉氏の特徴と言われる絶頂表現についても見てみましょう。「イク」とカタカナなら奈倉氏が多く、ひらがなならば柏木氏という傾向は出ています。が、カタカナにおける奈倉氏の割合が高いわけでもなく、優秀な判断材料としては弱いでしょう。一応「昇天」、「果て」といった奈倉氏特有の表現に注目しておきましょう。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| イッ | 106 | 48 | 58 |
| イク | 86 | 28 | 58 |
| イカ | 72 | 28 | 44 |
| イキ | 62 | 9 | 53 |
| イケ | 12 | 6 | 6 |
| いく | 33 | 31 | 2 |
| いき | 45 | 37 | 8 |
| 出し | 155 | 60 | 95 |
| 射精 | 92 | 57 | 35 |
| 出る | 60 | 31 | 29 |
| 果て | 46 | 8 | 38 |
| 絶頂 | 37 | 21 | 16 |
| 昇天 | 34 | 4 | 30 |
| 痙攣 | 23 | 6 | 17 |
擬音
同じく奈倉氏の特徴と言われる擬音についても見てみましょう。でも、多分part_of_speechの判断で、結構抜けがあると思います。需要があれば専用にマイニングしてみます。コメントかtwitterとかで気軽にイッてください。どっかで「ムク」は奈倉氏の代名詞だという投稿を見た気がしますが、そんなことはなさそうです。お互い使う擬音の傾向はありますが、いかんせん数が少ないので大きな判断材料にはならなそうです。
| 単語 | 全体 | 柏木 | 奈倉 |
|---|---|---|---|
| ムク | 36 | 18 | 18 |
| グチョグチョ | 13 | 3 | 10 |
| ピュッ | 13 | 0 | 13 |
| ドクドク | 13 | 0 | 13 |
| ヒクヒク | 10 | 3 | 7 |
| パンパン | 11 | 9 | 2 |
| ゴクン | 11 | 7 | 4 |
| ズンズン | 10 | 10 | 0 |
人間による奈倉柏木判断
ここで紹介した以外にも細かな表現による違いが結構見えました。 さて、ディープラーニングによる奈倉柏木判断を実装する前に、我々がwjnスレに直面したときの判断基準をこの結果を基に私なりに考えたので紹介します。この手法は結構な精度が出るので、皆様もお試しください。
-
柏木は消去法 というのも、柏木氏を特徴付ける決定的な文言や傾向が見当たらないことに起因します。だから例え、男性器や人物の表現が豊かだと言って、これは柏木氏だ、という安易な判断をすると痛い目を見ます。DF値が低いためです。ただ、柏木氏の確率は50%なので、「奈倉氏っぽくないな」っと思ったら柏木氏です。
-
下着の表現を見る 最初に見るのが下着です。柏木氏の文章ではほとんど下着が登場しません。出てくるのは「パンティー」と「ブリーフ」です。下着が「パンティー」だけでなく、「パンツ」「ブラ」や、特に「ショーツ」を使っていたりすると、十中八九奈倉氏です。「下着を脱がすのは1回だけ」なので同じ記事に複数回出ることは少ないことから、DF値も高いと思われ、非常に良い判断材料になるかと思われます。この判断基準は非常に覚えやすいので、皆様がまず身につけるべきは下着です。
-
和姦か強姦か 奈倉氏の特徴として強姦じみた表現(強姦しているわけではない)があることがあります。この判断基準は下着に比べると弱いですが、下着では分からない場合もあるので、これも念頭に置いた方がいいです。
-
奈倉氏の特徴的な単語 ざっと抽出した単語出現頻度を見ていると、柏木氏は非エロティックで一般的単語で奈倉氏の頻度を大きく上回っている場合が多いです。対し奈倉氏の表現の方が頻度が多い単語には、覚えやすい単語が目立ちます。紹介した「クリトリス」「男根」「昇天」「果て」や、「香り」「液体」「生理」「ダメ」といった単語も奈倉氏の頻度が高いです。ここまでで、奈倉氏の特徴に当てはまらなければ柏木氏、という判断を行います。
Tensorflowによる学習
さて、作成したデータセット(ベクトル化したデータと柏木奈倉ラベル)から学習を行っていきます。 ここで、データセットを訓練データ、評価データの2つに分ける必要があります。 これは、過学習を観測するため、すなわち新しい記事が出ても奈倉か柏木かを判定できるかどうか評価するために行います。学習は訓練データのみを用いて行い、最終的なモデルを評価データで評価します。 勿論、前章で作成した辞書も訓練データだけで作っています。 訓練データ、評価データの割合は8:2にしています。つまり今回では60点で評価してます。
ちなみに、この2つに分ける以外に検証データを作ったりすることもありますが、今回は行ってません。
とりあえずMLP(Multi Layer Perceptron)
ただのニューラルネットです。説明省きます。ディープではない4層(入力層、隠れ層2層、出力層)で試してみました。
| 層 | 長さ |
|---|---|
| 入力層 | 180 |
| 隠れ層1 | 50 |
| 隠れ層2 | 10 |
| 出力層 | 2 |
| その他 | 値 |
|---|---|
| 損失関数 | 交差エントロピー |
| オプティマイザー | momentum |
| 学習率 | 0.01 |
| dropout | 0.5 |
| epoch | 30000 |
結果、98%の精度が出ました。
これまで、データ数やTF-IDFやBoWやMLPで「今回は行ってません。」とか書いてきたのはこの精度が出たからです。 これ以上改良しようがパフォーマンスの向上が期待できないためです。 正直なところ、LSTM、GRUなどを使ってディープにしたいという思いはあったのですが、早々にこの精度が出てしまいました。 というわけで、このプロジェクトはこれにて完としたいです。
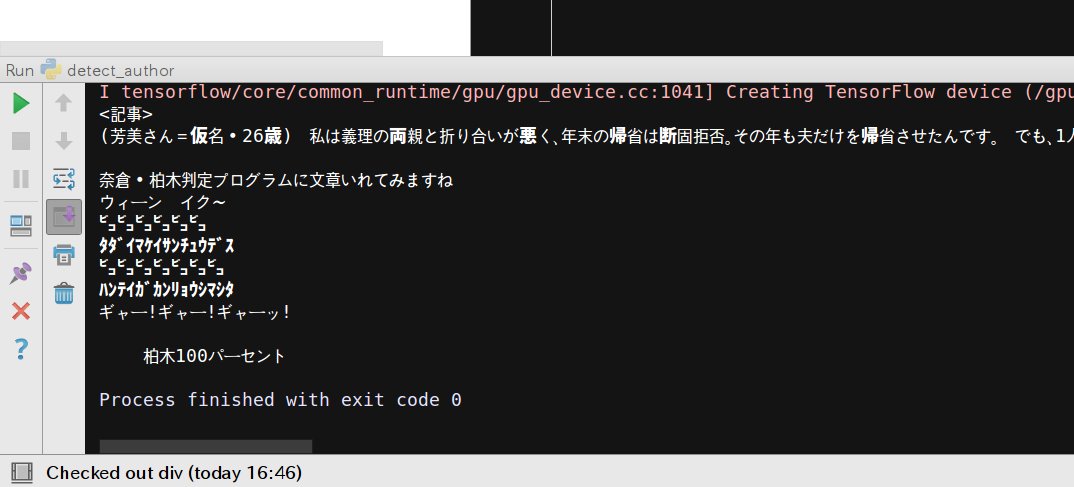
総括
- 最近wjnスレが少なくて寂しい。
今後の展望
- webアプリをそのうち(?)作ります。web系はやったことないので、勉強しながらになるため遅いと思います。というか就職関連で忙しいので遅いです。
(追記2017/07/12)できました 奈倉柏木判定プログラム(nakura-kashiwagi.hanarchy.biz)